조회 성능 개선을 위한 쿼리 최적화 (1)
개요 프로젝트를 되짚어보면서 개선할 수 있는 부분을 찾고 있습니다. 진행 중인 프로젝트는 콘서트 티켓팅 프로젝트로 많은 트래픽이 몰리는 상황을 가정하고 있습니다. 콘서트를 예매하는 과
taetae99.tistory.com
개요
이전 게시글에서는 조회 성능을 개선하기 위해 불필요한 컬럼이 있는지 확인한 뒤 제거했습니다.
그 결과, 성능이 다소 개선되었지만, 기대만큼 개선 효과를 얻지는 못했습니다.
이번에는 인덱스를 활용하여 성능을 개선해 보고자 합니다.
| 구분 | 기술 스택 |
| Language | Java 17 |
| Framework | Spring Boot 3.4.1 |
| DB | MySQL 8.0 |
| JPA | Hibernate 6.6.4 |
인덱스 적용 기준
이해를 돕기 위해 프로젝트의 실제 테이블 구조와는 약간 다르게 작성되었습니다.
인덱스를 적용하고자 하는 컬럼은 좌석 테이블에서 공연을 식별하는 session_id입니다.
인덱스를 적용하기 전에, 먼저 session_id 컬럼이 인덱스 활용에 적합한지 확인하고자 합니다.
따라서 인덱스 적용 기준을 먼저 살펴보겠습니다.
인덱스 적용 기준은 [우아한 테크]의 라라, 제로님의 유튜브 영상에서 참고하였습니다.
인덱스 적용 기준
- 카디널리티가 높은 컬럼
- WHERE, JOIN, ORDER BY 절에 자주 사용되는 컬럼
- INSERT/ UPDATE/ DELETE가 자주 발생하지 않는 컬럼
- 규모가 작지 않은 테이블
프로젝트 설명
인덱스 적용 기준을 만족하는지 확인하기에 앞서 프로젝트에 대한 설명을 간단히 하겠습니다.
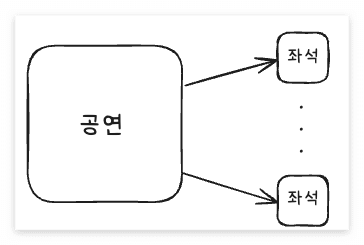
인덱스를 고민하는 테이블은 좌석 테이블입니다. 하나의 공연에 여러 개의 좌석 정보가 등록됩니다.

프로젝트의 좌석 선택 화면입니다. 공연을 예매하기 위해서는 좌석 정보 조회가 빈번하게 발생하게 됩니다.
많은 사용자가 공연 예매를 위해서 해당 페이지에 접속하고 좌석 정보 조회 요청이 발생합니다.
또한, 이미 예약된 좌석을 예매하려고 하는 경우 "이미 예약된 좌석입니다."라는 문구가 출력되며 좌석의 상태를 다시 조회해야 합니다.
그러므로 좌석 테이블에는 빈번한 조회가 발생하게 됩니다.
좌석 정보를 조회하는 서비스 코드
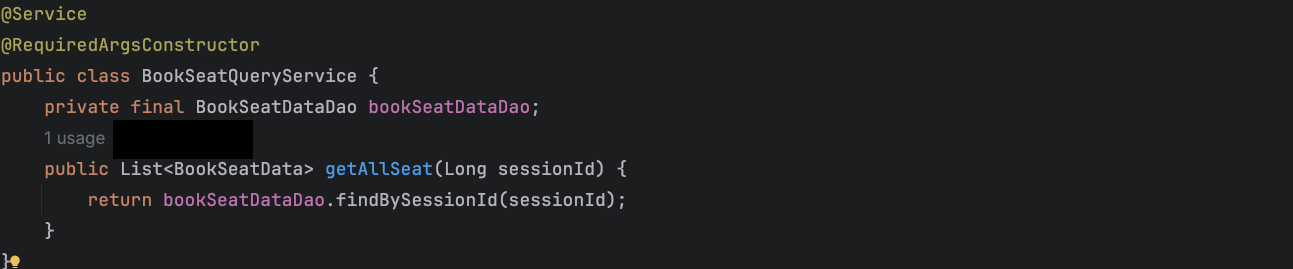
해당 서비스 코드는 공연 id(session_id)를 사용하여, 해당 공연에 등록된 좌석 정보를 모두 조회하여 반환합니다.
그러므로, 좌석 정보(BookSeatData)의 공연 id(session_id) 컬럼에 인덱스를 적용하고자 합니다.
인덱스 적용 기준 확인하기
위의 프로젝트 상황을 바탕으로 session_id에 대한 인덱스 적용 기준을 하나씩 확인해 보겠습니다.
1) 카디널리티가 높은 컬럼 ✅
인덱스를 통해 테이블의 레코드를 읽는 것은 인덱스를 거치지 않고 바로 테이블의 레코드를 읽는 것보다 높은 비용이 드는 작업입니다.
테이블에 레코드가 100만 건이 저장되어 있는데, 그중에서 50만 건을 읽어야 하는 쿼리가 있다고 가정해 보겠습니다.
전체 테이블을 읽어서 필요 없는 50만 건의 데이터를 버리는 것이 효율적인지, 인덱스를 통해 필요한 50만 건의 데이터만 읽어 오는 것이 효율적 일지 판단해야 합니다.
일반적인 DBMS의 옵티마이저에서는 인덱스를 통해 레코드 1건을 읽는 것이 테이블에서 직접 레코드 1건을 읽는 것보다 4~5배 정도 비용이 많이 드는 작업으로 예측합니다.
즉, 인덱스를 통해 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 이용하지 않고 테이블을 모두 읽어서 필요한 데이터만 가려내는 방식으로 처리하는 것이 효율적입니다.
서로 다른 공연이 100개가 존재한다고 가정해 보겠습니다.
공연마다 좌석의 개수가 1,000개라면, 좌석 테이블에는 총 100 * 1,000개로 약 10만 개의 데이터가 저장됩니다.
이 중에서 공연 id가 유니크한 값의 수는 100개로 카디널리티는 100입니다.
전체 테이블 레코드에서 session_id = 1인 경우를 조회하면, 10만 건에서 1,000건의 데이터가 조회될 것이고 이는 약 1%에 해당합니다.
반면, 성별 컬럼과 같이 남/여 두 개의 값만 존재하는 컬럼에 인덱스를 적용하면, 평균적으로 전체 테이블의 50%의 데이터를 조회하게 되어 효율이 떨어집니다.
따라서, session_id 컬럼은 카디널리티가 높다고 판단하였습니다.
2) WHERE, JOIN, ORDER BY 절에 자주 사용되는 컬럼 ✅

findBySessionId()을 사용한 좌석 정보 조회 시에는 위의 쿼리가 발생하게 됩니다.
좌석 테이블에서 공연 id(session_id)를 활용하여 좌석 데이터를 조회합니다.
이때 where절이 사용되는 것을 확인할 수 있습니다.
3) INSERT/ UPDATE/ DELETE가 자주 발생하지 않는 컬럼 ✅
인덱스를 사용하면, 저장되는 컬럼의 값을 이용해 항상 정렬된 상태를 유지해야 합니다.
그러므로 INSERT/UPDATE/DELETE의 처리 속도가 느려집니다.
대신 이미 정렬된 인덱스를 갖고 있기 때문에 SELECT의 처리는 빨라지게 됩니다.
본 프로젝트의 요구사항은 다음과 같습니다.
- 공연 등록은 사용자가 많지 않은 저녁 시간이나 새벽에 주로 진행됩니다.
- 공연 등록 시 좌석 정보도 함께 저장됩니다.
- 대부분의 트래픽은 특정 시점에 집중되는 좌석 정보 조회 요청에서 발생하기 때문에, 쓰기 작업보다 읽기 작업의 효율성이 더욱 중요합니다.
실제로 일반적인 웹 서비스와 같은 온라인 트랜잭션 환경에서 쓰기와 읽기 비율은 2:8 또는 1:9라고 합니다.
4) 규모가 작지 않은 테이블 ✅
100개의 공연에 각 좌석이 100개라면 1만 개의 데이터가, 100개의 공연에 각 좌석이 1,000개라면 10만 개의 데이터가 저장됩니다.
그러므로 규모가 매우 크다고 판단했습니다.
4개의 인덱스 적용 기준을 모두 만족하므로, session_id 컬럼에 인덱스를 사용해 보기로 결정했습니다.
인덱스 적용하기
인덱스 적용 기준을 만족하는 컬럼은 공연을 식별하는 session_id입니다.
그러므로 session_id에 인덱스를 적용하고,
session_id로 좌석 테이블을 조회하는 findBySessionId()의 성능을 개선해 보겠습니다.

jakarta.persistence에서 제공하는 기능으로 session_id에 idx_book_seat라는 인덱스를 적용했습니다.
nGrinder로 개선 효과 확인하기

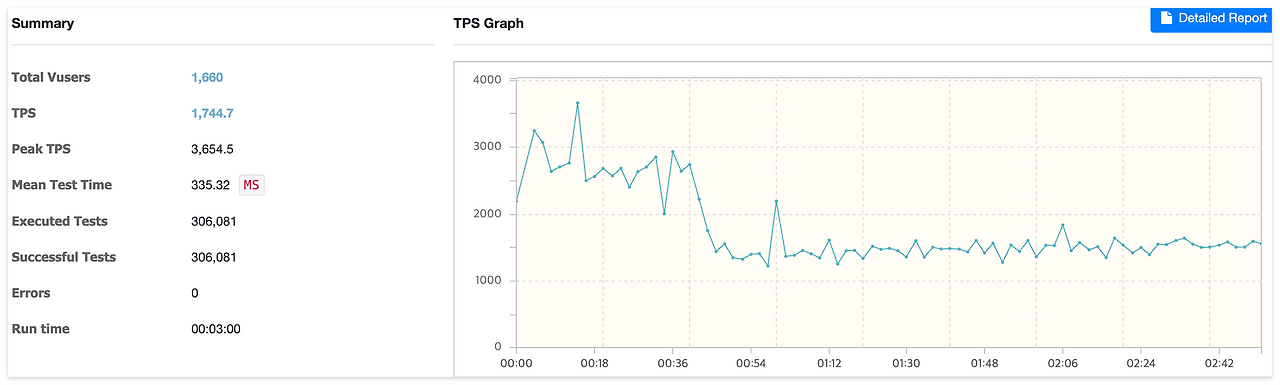
| 항목 | 컬럼 제거 후 (1차 개선) | 인덱스 (2차 개선) | 차이/개선 |
| vuser 수 | 1,660 | 1,660 | 동일 |
| TPS | 1,007.3 | 1,744.7 | 약 1.7배 증가 |
| MTT | 1,555.07 | 335.32 | 약 78% 감소 |
| 오류 발생 횟수 | 17 | 0 | 100% 감소 |
제가 목표했던 수치는 MTT를 400ms 이하로 줄이는 것이었습니다.
인덱스를 적용하여 목표했던 수치에 도달할 수 있었습니다.
다음 게시글에서는 @Transactional 사용 방식 변경에 대해 다뤄보겠습니다.
참고
Real MySQL 8.0 - 백은빈, 이성욱 저
https://www.youtube.com/watch?v=edpYzFgHbqs&t=349s
'트러블 슈팅' 카테고리의 다른 글
| [MySQL] DISTINCT 사용에 따른 임시 테이블 및 성능 차이 (0) | 2025.09.11 |
|---|---|
| 조회 성능 개선을 위한 @Transactional (3) (1) | 2025.08.25 |
| 조회 성능 개선을 위한 쿼리 최적화 (1) (0) | 2025.08.19 |
| [Redis] 캐싱을 사용하여 조회 성능 개선하기 (nGrinder) (5) | 2025.07.14 |